Skip to content
Submit
Close search
Home
Blog
About
Contact
Gambling Books
NEW BOOK: The Theory of Modern Baseball
Home
Blog
About
Contact
Gambling Books
NEW BOOK: The Theory of Modern Baseball
Submit
Search
expand/collapse
Gambling Books
Books to help you handicap better
Baseball Handicapping
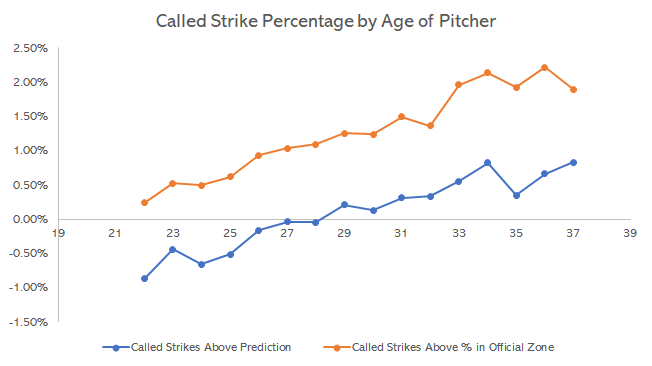
Veteran Bias in MLB Umpiring: Hitters
February 24, 2020
In the previous post we showed that umpires gave more calls to veteran pitchers, although part of this was due to veteran pitchers having better ac...
Read more
Sprint Speed, Exit Velocity, and Steamer Projections
February 20, 2020
The Steamer projections are the best baseball projections available where it is possible to get years of back historical data. It is possible there...
Read more
Veteran Bias in MLB Umpiring: Pitchers
February 20, 2020
With a little kid at home I don't have much time to enjoy televised baseball nowadays, but I used to watch a decent amount of NPB baseball. One of ...
Read more
Swinging at the First Pitch: Teams are Finally Catching On
February 16, 2020
Not all of the increase in offense over the past few years has been due to juiced balls, seam heights, or some other type of conspiracy like undete...
Read more
Throwing the Cutter and Beating the Market
February 14, 2020
For those of you hoping to build that game-changing model and get that free money betting the big leagues this year, rest assured there are few ine...
Read more
Pitch Sequencing: Breaking Balls ahead in the Count
February 13, 2020
For most pitchers the breaking ball below the zone but high enough for the hitter to be tempted to swing is by far the best pitch in a 0-2 or 1-2 c...
Read more
View all
Football Handicapping
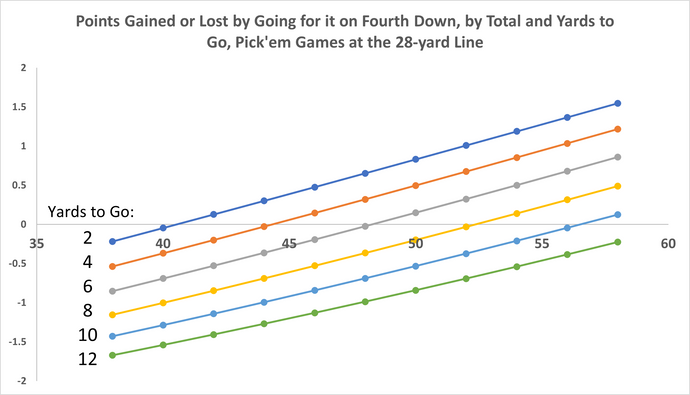
Fourth Down: Punting is Worse than Ever Before
These days in the NFL, the most obvious situations such as 4th and 1 and 4th and short near midfield are now reliably attempted by all but the wors...
Read more
The Greatest Angles Ever - #2: Under Every NFL QB Prop
In 2020 NFL props are an accepted mainstream bet, and if anything, I tend to see more prop picks than full game side/total wagers on the typical to...
Read more
The Greatest Angles Ever - #3: Home in the DEL
Those who bet the NHL seriously at all know that the lines are pretty sharp with any large moves mostly due to injury or goalie announcements. Usin...
Read more
The Greatest Angles Ever - #4: Under 10.5
As football begins again, sort of, I am reminded of one of the very best football prop angles of all time, first and second half team total under 1...
Read more
The Greatest Angles Ever - #5: All Over in Durango
Most of the money I have made has been on dead obvious angles that could have been bet blind every single day if one only knew what the angles were...
Read more
The Best Historical Weather Data Site for Sports Betting
As we all know these days, data is power, to the point that it can easily be used to destroy a country or continent. That is beyond the scope of ou...
Read more
View all